Dear reader, it is hot. I write this editorial next to four strategically opened windows. This week’s heatwave prevented my ageing laptop from joining any video calls this week. What does our future look like? It’s going to be one where we use less energy, by choice or by force majeure.
Fortunately it seems things will cool down before I need to spend a week in a tent at DWeb camp. The schedule’s been announced, and worm-blossom has three events: The Willow Skill Tree, a Sneakerweb workshop, and Sneakerweb at the ‘demo night market’.
Sneakerweb has been the most prep. It needs some sites on it to give people an idea of what’s possible, so I’ve created sammy’s guide to the sneakerweb. My plan is to never publish this website on the world wide web. If you want to see it you’ll need to get it from me, or one of my friends, or one of my friend’s friends (etc), and import it into your sneakerweb collection. Aljoscha has also been preparing a few things for the sneakerweb, things which I have made drawings for that I will let Aljoscha choose whether to share or not (how firmly does he believe in the law of the sneakerweb?).
I’ve also been doing some grant proposal writing for the sneakerweb. Although this kind of writing is very annoying to do, at least it sort of forces you to express your stupid ideas as clearly as possible. Some of that writing I folded back into the upcoming sneakerweb site for the www, which is ready to go but for the downloads page. My funding ideas revolve around the question of whether we can harden the sneakerweb enough that it becomes useful in adversarial environments. I think there’s some obvious things we could try in this direction.
Anyway, this time next week I’ll be in Germany, writing an update from my tent. I need a palette cleanser.
~sammy

A couple things I want to report. First, the folks implementing Bab in Zig found a bug in our own implementation that resulted in incorrect WILLIAM3 digests. And then I found some more bugs. I've managed to fix everything I could identify, but our implementation still appears to diverge from BLAKE3 in ways that it shouldn’t. So no complete fixes published yet.
Second, Dan and I went on a fun spiritual journey to discover the true meaning of Ufotofu. Okay, maybe it was slightly less grand. But we did learn something about when to treat producers as being equal (or, more technically correct, as being equivalent in the finest sensible way).
The obvious approach is to consider two producers as equal if they exhibit the same observable behaviour in terms of yielded items, final values, and error values. Given that bulk production must be equivalent to item-by-item production and given that slurping is a transparent optimisation detail, this observable behaviour should be independent on which method calls are being used. Or so we thought. At the end of a long debugging session, we realised that actually slurping is not completely transparent. If it was, it would have to return the unit type after all, but it is allowed to report errors instead. And this can be relevant: we encountered a situation where it was absolutely sensible for slurping to yield a different error than the error that would be yielded when attempting to produce an item from the exact same state.
This left us with two choices: either allow observable side-effects when slurping (and, dually, flushing) and remove the check for error equality from ProducerExt::equals, or change the return type of slurp and flush to (). The latter is the cleaner solution mathematically, and would arguably be appropriate in a lazy language such as Haskell. And for slurping, infallibility is easy difficult to justify: producers already have to buffer any error they encounter if they encounter some items first. But the part that is difficult to justify is infallible flushing. A flush method that fails silently and delays reporting any encountered error until when you try to write the next item (or the final value, i.e., you close the consumer) feels, uhm, difficult to justify, to put it mildly. Flushing corresponds to fsync in the UNIX world after all, and a silently failing fsync is utterly absurd.
So we left the API unchanged and adjusted the mental model of producer equality instead. Because we are nothing if not pragmatic here at worm-blossom, especially when it comes to ufotofu.
 And third and finally, I can reveal the secret side project I briefly mentioned a while ago: using the same tool as I use for the weekly background music, I made an album. For now, Commputer Has No Feelings will be distributed via sneakerweb only, and it features catchy titles such as Your deductions are only as good as your initial assumptions and Sometimes you need to wait a while before you can think about flowers again, but seeing flowers speeds up the process. Sammy drew the lovely cover artwork you can see to the right.
And third and finally, I can reveal the secret side project I briefly mentioned a while ago: using the same tool as I use for the weekly background music, I made an album. For now, Commputer Has No Feelings will be distributed via sneakerweb only, and it features catchy titles such as Your deductions are only as good as your initial assumptions and Sometimes you need to wait a while before you can think about flowers again, but seeing flowers speeds up the process. Sammy drew the lovely cover artwork you can see to the right.
 And around May, I accidentally finished a second album. Circumference has longer songs with shorter titles. And will also be available only via sneakernet for a while.
And around May, I accidentally finished a second album. Circumference has longer songs with shorter titles. And will also be available only via sneakernet for a while.
It is so enjoyable to go beyond short looping background music, and to devote more time to polishing the tracks. And despite the restrictive songwriting tool and the occasional goofy song title, making these albums was actually a form of emotional processing. So I hope that some of that music will resonate with others. I am excited to finally have the custom software that was 100% necessary to share these.
~Aljoscha



















































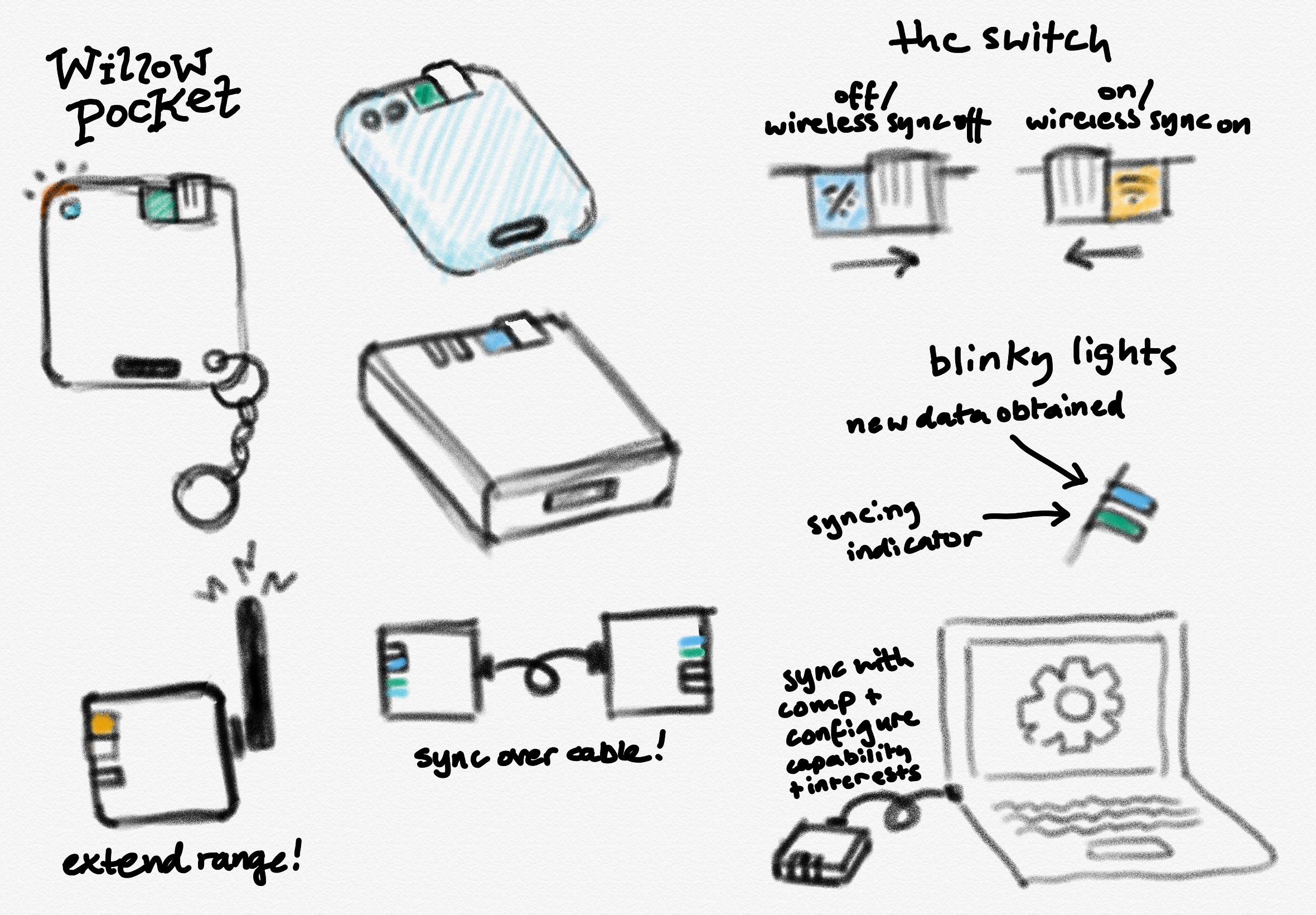

 We have been teasing the
We have been teasing the